NVIDIA and the PyTorch team at Meta announced a groundbreaking collaboration that brings federated learning (FL) capabilities to mobile devices through the integration of NVIDIA FLARE and ExecuTorch.
NVIDIA FLARE is a domain-agnostic, open-source, extensible SDK that enables researchers and data scientists to adapt existing machine learning or deep learning workflows to a federated paradigm. It also enables platform developers to build a secure, privacy-preserving offering for a distributed multi-party collaboration.
ExecuTorch is an end-to-end solution for enabling on-device inference and training capabilities across mobile and edge devices. It is part of the PyTorch Edge ecosystem and enables efficient deployment of various PyTorch models to edge devices.
By integrating the two, we offer a solution for you to leverage the power of FL on mobile devices while preserving user privacy and data security. To enable cross-device FL, there are two critical components:
- An FL environment that is capable of orchestrating proper learning flow with a participant pool consisting of millions of devices.
- An effective on-device training workflow, preferably easy to migrate from the your existing development environment.
With the collaboration between NVIDIA FLARE and ExecuTorch, you can now define your model architecture and training parameters using familiar PyTorch code and migrate it to cross-device FL paradigm:
- NVIDIA FLARE handles the cross-device FL process with new modules designed for edge applications, both for federated workflow, and for on-device development.
- ExecuTorch enables the edge-side training and easy migration from existing PyTorch solutions.
To support large-scale deployments, NVIDIA FLARE implements a hierarchical FL architecture, enabling the efficient management of a large number of edge devices. This solution ensures reliable and scalable model training across distributed mobile devices while keeping all data local.
NVIDIA FLARE and ExecuTorch are democratizing edge AI training on mobile devices by making it more accessible and efficient while preserving privacy in decentralized AI:
- Effortless development: Abstracted device complexity, handling hardware, OS, ML frameworks, and programming languages for seamless FL on mobile.
- Streamlined prototyping: Device Simulator to simulate a large number of devices.
- Industrial-ready federated deployment: Cross-device FL system supporting a large number of devices.
With this framework, data scientists can focus solely on defining model architecture and training parameters in PyTorch, and federated pipeline design.
Collaborative model learning on distributed edge devices
Many AI models and applications rely on everyday data that is generated at edge devices in people’s daily life: for example, predictive text and speech recognition, smart home automation, autonomous driving, traffic prediction, and fraud detection for financial services. Using millions of AI-enabled devices, a major proportion of data used by AI will be generated at the edge.
Unlike specialized datasets such as in enterprise—typically curated, structured, labeled under controlled conditions, and stored in centralized silos—everyday data on the edge is highly dynamic, influenced by individual user behaviors, environmental factors, and specific conditions across heterogeneous devices.
AI model training usually prefers stable data access, fast communication channels, abundant computation resources, and controlled data diversity. For everyday data with such a dynamic and distributed nature, a basic and simple solution is to collect data from diverse sources to a central location for training.
However, edge-based applications are usually restricted by strong privacy constraints and practical limitations, making centralized training infeasible.
In this case, FL across distributed edge devices becomes a potential solution. Nevertheless, it is still challenging to collaboratively train robust AI models based on data collected at edge devices, due to intermittent device connectivity, limited communication bandwidth, variable device capabilities, and highly heterogeneous data distributions.
To properly address these challenges and enable effective AI model learning in a distributed fashion, a well-designed FL framework with on-device functionalities can play an important role in effectively leveraging all data from a diverse set of devices.
Such an FL framework must have the capability to handle the following:
- The large scale of participating devices, as the candidate pool size is often at a scale of millions.
- Different operating systems and hardware environments leading to high device programming complexity.
- Challenges from limited computation capacity and communication bandwidth.
- Challenges caused by connectivity, such as devices joining and leaving at any time.
Therefore, the framework must properly orchestrate the model update and aggregation aspects of a federated pipeline and address these challenges.
| Challenge | Solution |
| Large numbers of devices | NVIDIA FLARE designed a hierarchical communication and aggregation mechanism, such that a logical tree-structure is utilized to achieve exponential efficiency in dealing with thousands of concurrent connections. |
| Different operating systems and hardware environments | Meta ExecuTorch achieves streamlined cross-platform deployment with NVIDIA FLARE edge modules. |
| Limited computation capacity and communication bandwidth | NVFLARE enables you to use efficient models, compress updates with longer local training, and either optimize client selection or use hierarchical FL to reduce compute, communication, and bandwidth costs. |
| Connectivity | NVIDIA FLARE provides robust solutions and the flexibility to account for different scenarios and use cases. |
Hierarchical FL for cross-device applications
With the single-layered FL pipeline, a global server directly communicates with clients and uses simple logic to collect and aggregate model updates. However, for cross-device use cases where you potentially have tens of thousands of concurrent devices from a pool of millions of participants, the basic single-layer communication structure can’t perform.

NVIDIA FLARE developed a hierarchical FL system, with a tree-structured architecture (Figure.1):
- Server: Provides functionality of overall orchestration, global evaluation, job and task preparation, and so on.
- Aggregators: Perform task routing from server to leaf nodes and result aggregation from the leaf nodes back to the server.
- Leaf nodes: The only ones interacting with the edge devices. Devices connect to leaf nodes through web gateways, which are deployed with multiple instances for web infrastructure scalability.
By adding multiple layers of aggregation, we optimized the affordable and robust workload distribution on each node of the system. With such a robust hierarchy, advanced FL algorithms can be easily implemented and scaled. This tree hierarchy is logical and the physical connections and communication routes between nodes could be further optimized according to the network condition.
By using web gateways through HTTPS, we ensure that each device is properly connected with encryption guarantees, and that its data is transmitted to the appropriate FL clients safely for processing. The web gateway also handles device registration, session management, and load balancing, optimizing connectivity for large-scale deployments. This approach offers a scalable solution to supporting potentially millions of edge devices or mobile phones in an FL scenario.
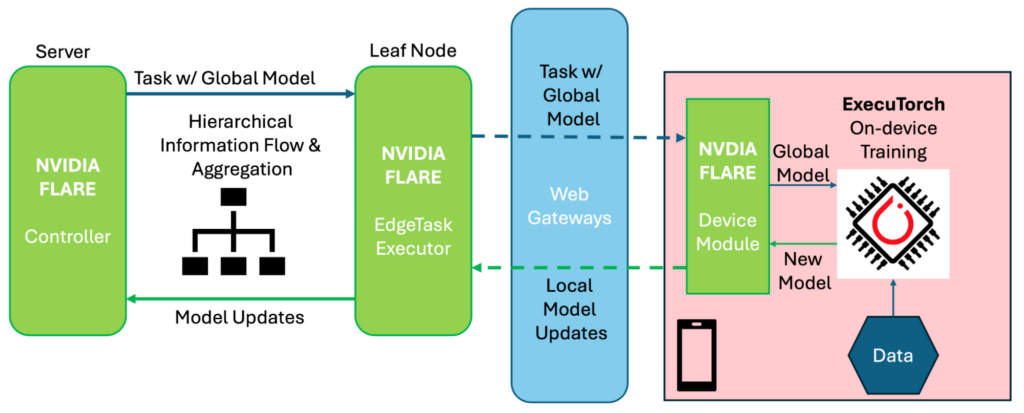
Figure 2 shows how NVIDIA FLARE and ExecuTorch work together step-by-step to enable cross-device FL:
- The FLARE Controller on the server first prepares a task containing the global model, and dispatches it through the hierarchical system until it reaches the leaf node.
- The FLARE
EdgeTaskExecutoron the leaf node processes the task, exports the global model to the ExecuTorch format (if the Controller has not done it), and sends the task to individual devices through web gateways. - On the device, the
Devicemodule of NVIDIA FLARE bridges the FL system and on-device training pipelines, where ExecuTorch loads the received global model, performs on-device training with local data, and sends the new model to theDevicemodule. - The
Devicemodule then prepares a message containing the local model updates (the difference between global model and new model, potentially reinforced with privacy-protection mechanisms) and sends the updates back to the FLAREEdgeTaskExecutor. - The FLARE
EdgeTaskExecutorthen processes the received updates and sends it through the hierarchical system where the updates from different sources are aggregated layer-by-layer. - Upon receiving the top-level aggregated model updates, the FLARE Controller evaluates and prepares the new global model for the next task assignment.
Effortless cross-device federated pipeline development
With the support from NVIDIA FLARE and ExecuTorch, we provide a streamlined cross-device FL pipeline for you, enabling an efficient general workflow with customizable components, such that you can focus on innovation without worrying about the underlying infrastructure development.
On the device-side, the Device module establishes a core training workflow (for example, Objective-C on iOS), which serves as the bridge between FL system and on-device training, providing you with configurable parameters and privacy settings. It handles the heterogeneous hardware, OS, ML frameworks, and programming languages with abstracted device complexity.
Using ExecuTorch, you focus on developing novel models and training recipes, which can then be easily migrated to a device platform.
On the federated pipeline side, you define customized FL schemes, for example, synchronized or asynchronized with NVIDIA FLARE’s Controller API. Customizable aggregators provide versatile options that best fit the needs of specific learning goals. A collection of commonly used controllers and aggregators from NVIDIA FLARE can be applied as defaults.
Everything else, from global model distribution and local task execution to collecting model updates for producing new global models, is taken care of automatically, liberating you from complicated implementation details.
In addition, we provide DeviceSimulators to perform local FL end-to-end simulations of mobile applications. This provides a flexible mechanism for prototyping, covering model training based on user-chosen training recipes.
For example, you can experiment with a PyTorch-based trainer and compare it with an ExecuTorch-based version to make sure that the to-be-deployed ExecuTorch solution aligns with the PyTorch counterpart. You can also experiment with different aggregators to test their performance under realistic settings.
In other words, you can prototype your cross-device FL pipelines using Python and perform end-to-end local simulations for the entire FL study, the same as you would for other model learning processes using NVIDIA FLARE.
Next, you can migrate and deploy the prototype to a real cross-device FL system with ease. There’s no need to switch to mobile platform development with other languages (for Objective-C, Swift, Java, or Kotlin) or to worry about network connectivity and routings. NVIDIA FLARE and ExecuTorch together handle all device-specific training requirements, and federated orchestrations.
Running NVFlare Mobile example
To get you started, we’ve provided examples to show this simulation process. In the Running NVFlare Mobile Example, we currently cover the following applications under two training schemes:
hello_mobile: A simple job with a list of numbers to test the edge functions including hierarchical aggregation and task handling. Shows the federated process.xor_mobileandxor_mobile_pt: Train a super-light neural network for a simple xor logic task with fixed data for all participants, using both ExecuTorch and regular PyTorch trainers. Shows a pipeline with neural network training.cifar10_mobileandcifar10_mobile_pt: Train a convolutional neural network for a standard CIFAR-10 classification task. Both ExecuTorch and PyTorch schemes are provided. In this case, each participant trains on different subsets of CIFAR-10, simulating a more realistic cross-device collaboration.
For real-world deployment, the process includes three parts:
- Setting up NVIDIA FLARE
- Enabling training on edge devices through ExecuTorch
- Performing FL sessions
The study starts with setting up the NVIDIA FLARE system, including provisioning the system, and setting up the web gateways, which can be as simple as two commands:
python nvflare/edge/tree_prov.py -r /tmp -p edge_example -d 1 -w 2
python nvflare/edge/web/routing_proxy.py 5000 /tmp/edge_example/lcp_map.json
For more information, see the Running NVFlare Mobile Example.
After setting up the environment, start each node with the script in their startup kits:
On the edge device side, we’ve developed a demo iOS app to showcase the capability. In this demo app, you configure the proxy server’s IP address and PORT number, and then initiate the training process (Figure 3).
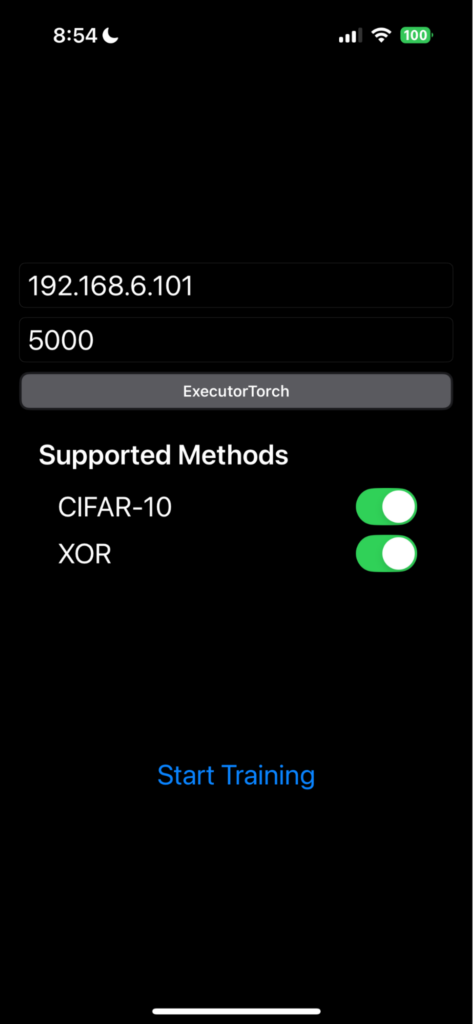
The app then connects to the FL system through the proxy server (Figure 1) and waits for the task assignment.
The training only begins after a job has been submitted to the NVFlare system. The Controller assigns the specific task to the edge device through the mechanism (Figure 2).
To kick-start an FL session, the admin verifies the global configurations (for example, model format and weights), and submits the job to start NVIDIA FLARE training as usual in NVFlare admin console:
submit_job cifar10_mobile_et
The rest of federated orchestration is automatically taken care of by NVIDIA FLARE, and the local on-device training is taken care of by ExecuTorch.
Summary
The NVIDIA FLARE and Meta PyTorch team collaboration represents a significant advance in mobile FL, offering a holistic approach for developing cross-device FL solutions. This pipeline helps handle the complexities of mobile deployment and federated training behind the scenes.
Through the NVIDIA FLARE hierarchical architecture, the platform can efficiently manage millions of edge devices, making large-scale mobileFL practical and accessible. Data scientists can focus on core expertise, defining models and training parameters in Python, while NVIDIA FLARE and ExecuTorch handle the intricate details of mobile deployment, federated orchestration, and training scalability. This innovative approach maintains data privacy and security while enabling efficient model training across distributed devices.
The collaboration between NVIDIA and the PyTorch team at Meta marks a significant step forward in democratizing FL for mobile applications, opening new possibilities for privacy-preserving and decentralized AI development at the edge. The two teams are continuing their collaboration to enhance this solution.
With the goal of democratizing on-device training across various devices, we started with iOS, and will follow with Android and other edge devices.
For more information, see the following resources:
To connect with the NVIDIA FLARE team, contact federatedlearning@nvidia.com.
Acknowledgement
Thanks to the PyTorch team at Meta for their help with this post.